論文読み「ReFT- Representation Finetuning for Language Models」
プチ話題になったReFTの論文読んでみた.
ReFT: Representation Finetuning for Language Models
忙しい人向けに
この論文がやったことは主に3つです.
- LoRAなどの他のParameter Efficient FineTuning(PEFT)と違って,モデルの重みではなく表現に介入することを考えたよ
- その表現に介入する手法として,ReFTを定義し,その中のReFTという手法を提案したよ
- ReFTはLoRAと比べて精度がよく,さらに10~65倍効率よく学習を進めることができるよ
導入と背景
事前学習済みの言語モデルを特定のドメインやタスクに適応するためには,Finetuneをする必要がある.Finetuneは事前学習よりも少ないデータで行われるが,近年は大規模言語モデルが大規模化しているので,Finetuneもまた莫大な計算が必要である.そこで,最近はParameter-Efficient FineTuning(PEFT)が注目されている.PEFTはモデルの全体を学習するのではなく,一部のみを学習することで効率的に学習を進める手法である.
ほとんどのPEFT手法は,モデルの内部の重み(パラメータ)に介入することを考えている.しかし,さまざまな研究結果で,モデルの隠れ表現は意味的な表現を多く保持しており,その表現に介入することでモデルのパフォーマンスを左右することができると示されている.そこで,この論文では,モデル内部の重みではなく表現に介入して学習を効率化することを考えた.
関連研究
PEFTs
PEFTは主に以下の3つのカテゴリに分類できる
- Adapter-based methods: 事前学習済みモデルのパラメータは固定し,最後の層のみを学習する手法[1,2,3,4,5,6]
- LoRA & DoRA: 重み更新の差分を近似行列で学習し,重みを更新する[7,8]
- Prompt-based methods: 入力するトークンエンべディングを学習すれ(最初の層のみを学習する)[9]
Representation editing
導入と背景でも述べたとおり,最近の研究[10,11,12,13,14,15,16,17,18,19]によって,さまざまな表現への介入によってFinetuneをすることなくモデルのパフォーマンスを制御できることが示されている.このことから,事前学習によってモデルの隠れ表現が意味的表現をうまく捉えられていることがわかる
Interventional interpretability
また,モデルの振る舞いを解明するためにモデルの隠れ表現に介入する研究も近年盛んに行われている[20,21,22,23].特に線型空間への介入は,人間が解釈可能な理論の発見に貢献している.
ReFT
記号などの準備
説明をシンプルにするため,Transformer-based言語モデルのみで考える. $n$個のトークンからなる入力$\mathbf{x}=(x_1,\cdots,x_n)$に対するモデルの最初の内部表現を$\mathbf{h}^{(0)}=(h_1^{(0)},\cdots,h_n^{(0)})$とする.$m$層からなるモデルの$j$番目の表現$\mathbf{h}^{(j)}$とし,最後の表現を$\mathbf{h}^{(m)}$とする.そして,モデルは出力トークンの生成確率$p(x_{x+1}\mid x_1,\cdots,x_n)=\text{softmax}(\mathbf{W}h_n^{(m)})$を計算する.
動機
背景でも述べたとおり,表現への介入によってモデルの表現の因果的な役割を解明する研究が行われている.その中でもInterchange intervention[24]は,内部表現をモデルに固定された値を入力した場合の表現に変更し,それによってモデルの振る舞いがどのように変化するかを観察することで因果的な役割を解明している.
一般に,言語モデルの表現は線形部分空間にエンコードされているため,この研究ではInterchange interventionの中のDistributed interchange intervention(DII)を用いる.DIIは以下のように表現に介入する:
\[\begin{equation} \text{DII}(\mathbf{b},\mathbf{s},\mathbf{R})=\mathbf b+\mathbf R^\top(\mathbf R \mathbf s-\mathbf R\mathbf b) \tag{1} \end{equation}\]ここで,$\mathbf{b}$通常の入力によって得られた表現で,$\mathbf{s}$は固定した値を入力した際に得られる表現で,$\mathbf{R}\in\mathbb{R}^{r\times d}$は低ランク変換行列であり,$d$がモデルの隠れ次元,$r$が部分空間の次元である.
これはつまり,元の表現$\mathbf{b}$と固定された表現$\mathbf{s}$の差を線形部分空間で表し,その部分空間で表された差だけ表現を変更することを意味している.そして,変更後の表現が$\mathbf{s}$に最も近づくように部分空間$\mathbf{R}$を学習し,$\mathbf{R}$を解釈することで元の表現$\mathbf{b}$の因果的役割を解明する.
この表現への介入方法を参考にして,ReFTを考えている.
Low-Rank ReFT instantiations
ReFTを表現に介入するPEFT手法の総称として定義し,この論文ではその中の一手法としてLow-Rank ReFT(LoReFT)を提案している.LoReFTは式(1)を以下のように変えている:
\[\begin{equation} \Phi_{\text{LoReFT}}(\mathbf{h})=\mathbf{h}+\mathbf{R}^\top(\mathbf{Wh}+\mathbf{b}-\mathbf{Rh}) \tag{2} \end{equation}\]これは,式(1)における$\mathbf{s}$を$\mathbf{Wh}+\mathbf{b}$として学習するということである
また,このLoReFTの簡易版として,DiReFTも提案している.DiReFTは以下のようにしている:
\[\begin{equation} \Phi_{\text{DiReFT}}(\mathbf{h})=\mathbf{h}+\mathbf{W}_2^\top(\mathbf{W_1h}+\mathbf{b}) \tag{3} \end{equation}\]これはLoReFTにおける線形部分空間への射影を省略し,ただ表現を変換するだけにした場合である.これとの精度の差分を見ることでLoReFTの線形部分空間への射影の効果を見ることができる.
訓練方法
入力の系列$\mathbf{x}=(x_1,\cdots,x_n)$と教師データ$\mathbf{y}=(y_1,\cdots,y_m)$について,cross entropy lossを最小化するように$\Phi$のパラメータ($\mathbf{W},\mathbf{b},\mathbf{R}$)を訓練する:
\[\min_\phi\left\{-\sum_{i=1}^m\log p_{\Phi}(y_i\mid\mathbf{xy}_{<i} \right\} \tag{4}\]実験
ReFTの効率性と精度を他のPEFT手法と比較する.実験は20以上のデータセットとRoBERTa(125M)からLLaMA(13B)までの幅広いモデルを用いた.
常識的推論
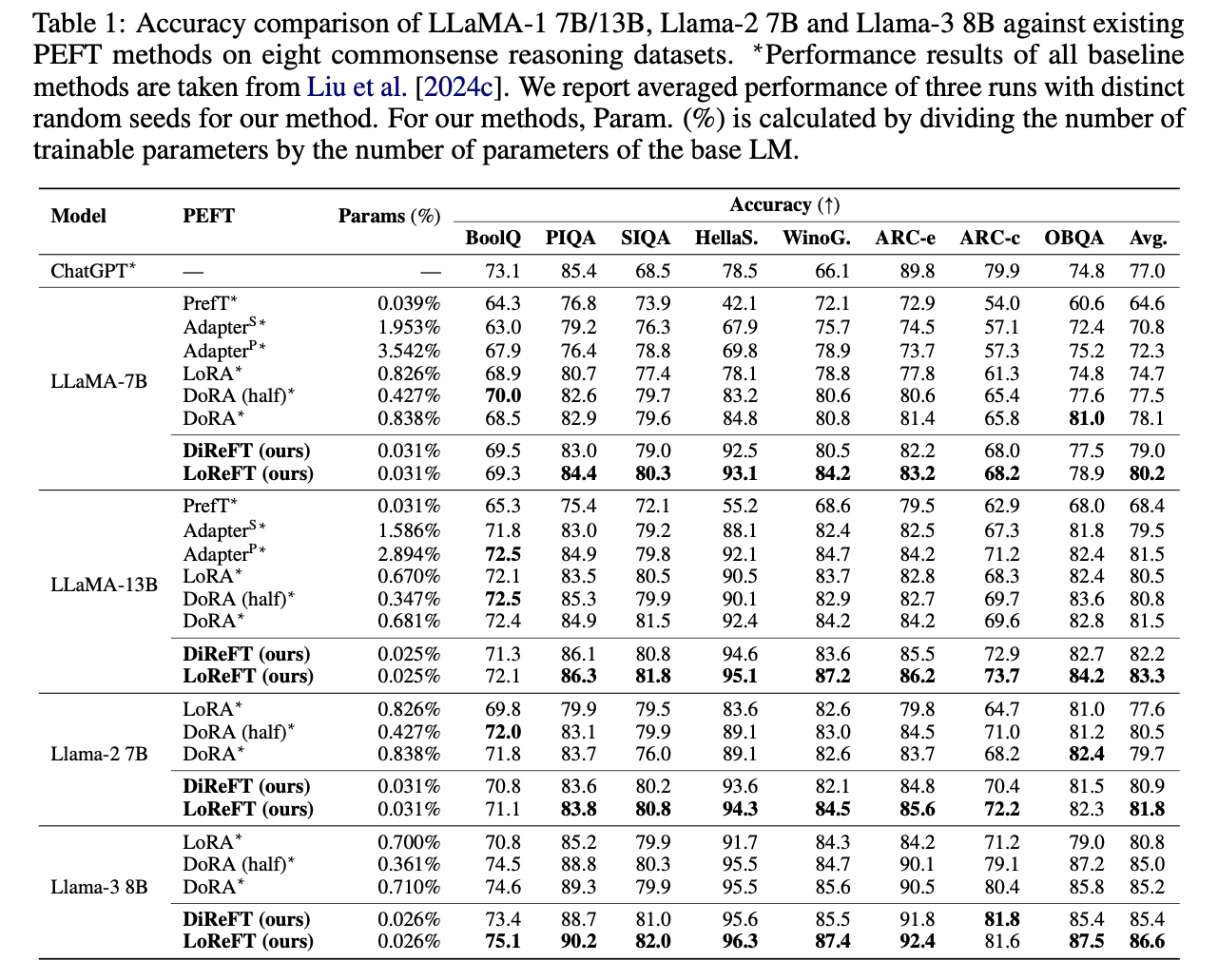
常識的推論における8つのデータセットを用いて比較実験を行った.その結果がTable 1である.これを確認すると,ほぼ全てのモデルとデータセットにおいて,他のPEFT手法よりもLoReFTの精度が上回っている.さらに,DiReFTよりもLoReFTが上回っていることから,部分空間への射影の重要性がわかる
算術推論
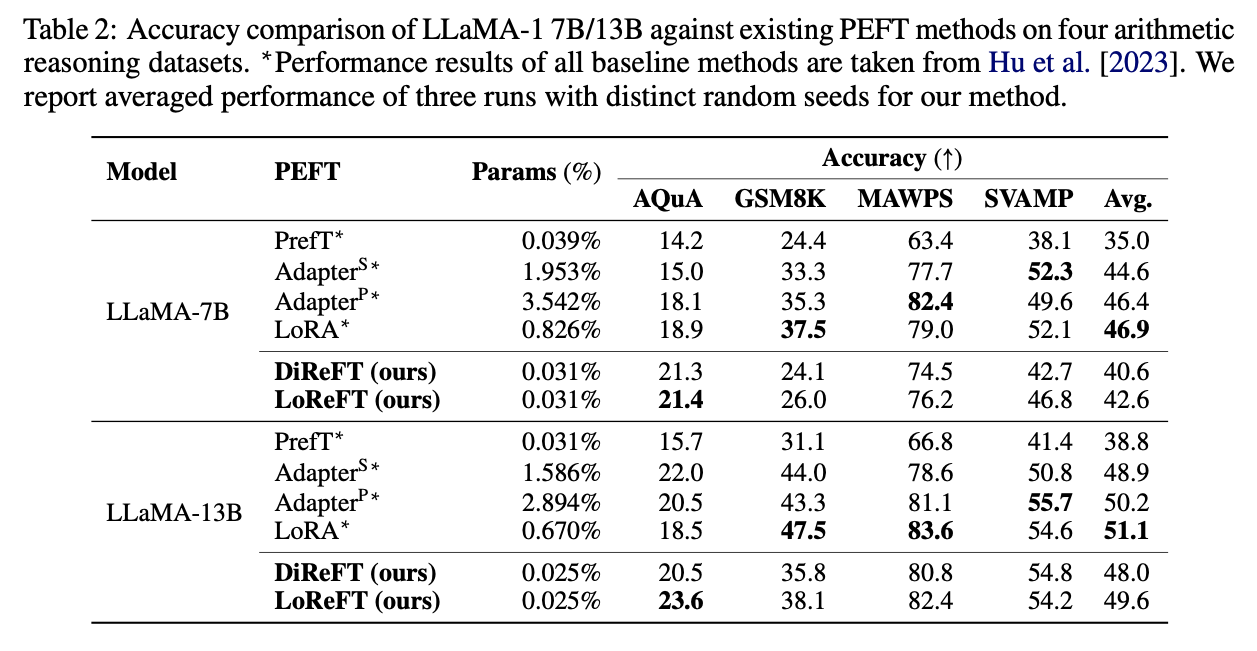
算術推論において4つのデータセットを用いて比較実験を行った結果をTable 2に示している.この場合,LoReFTは他のPEFT手法よりも精度が上回っていない.このことから,LoReFTはchain-of-thoughtなどの系列長の長いタスクにおいてはまだ研究の余地があることがわかる.
指示準拠
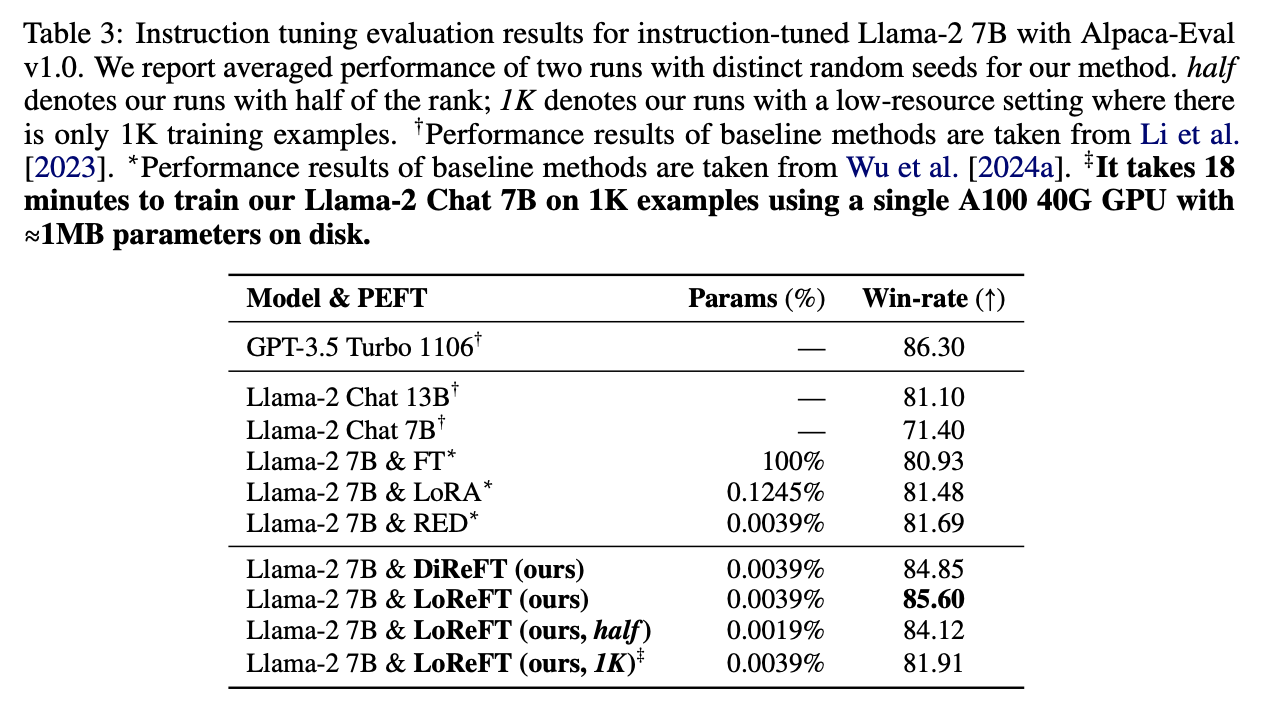
Instruction-Tuningにおける実験の結果がTable 3である.この場合には,LoReFTが他のPEFT手法を上回っており,ReFTの貢献が確認できる
自然言語理解
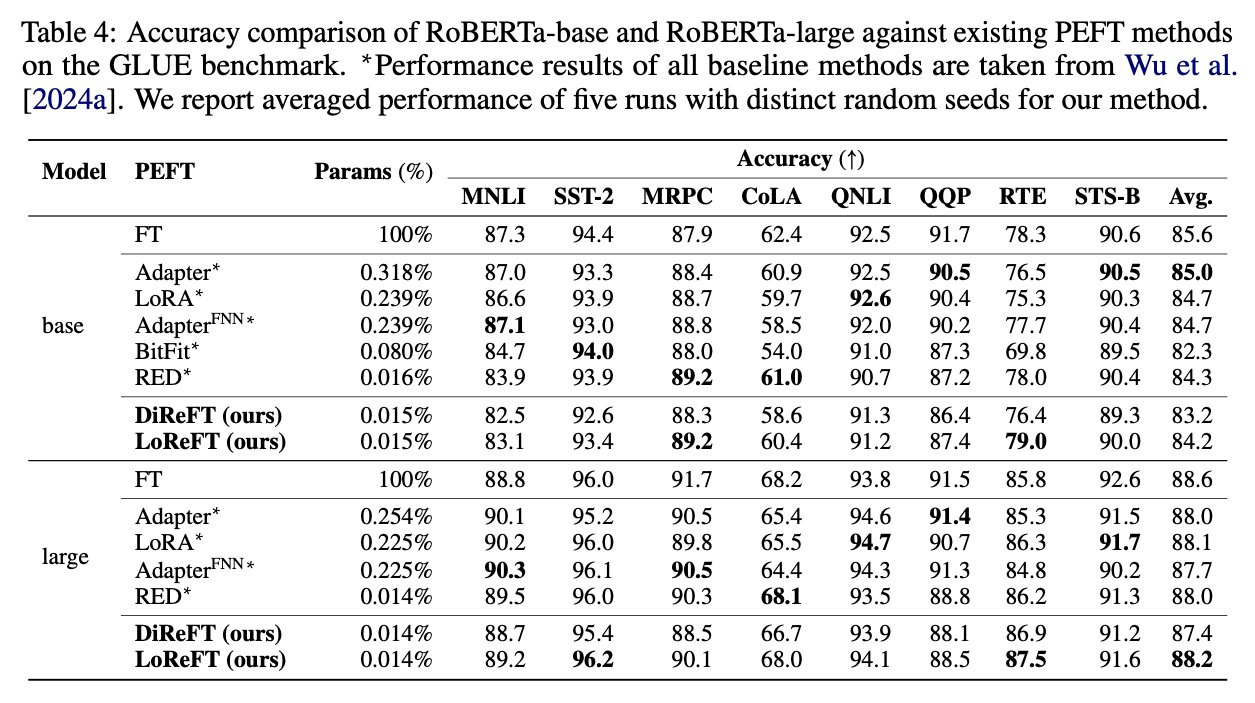
自然言語理解については,8つのデータセットで実験を行い,ReFTが他のPEFT手法とほぼ同じ精度であることが確認できた.
実験結果
全体として,ReFTは他のPEFT手法と同等以上の精度-効率性のバランスを示せた.
ReFTの限界
ReFTの貢献
ReFTはさまざまなデータセットで良いパフォーマンスを示したが,これは上流タスクにのみ現れる効果である可能性がある.つまり,モデル本来の性能を高めているわけではない可能性がある.(数式の意味を考えず,ただテストで点が取れるように勉強しているだけみたいなもの.)今後は,モデル本来の性能を高められるReFTの開発をすることが考えられる.
実験の信憑性
この論文での実験では,それぞれの手法のハイパーパラメータチューニングを行なっていないため.実験結果に多少のずれが生じる可能性がある.
まとめと感想
これまで学習というと重みを更新することというように思っていたが,隠れ表現を更新するという発想はとても面白かった.さらに,精度-効率性ともに良いパフォーマンスを示していることから実用性も高いのかなと思った.今後もReFTの研究の動向を伺っていきたい.
参考文献
[1]: Parameter-efficient transfer learning for NLP
[2]: MAD-X: An Adapter-Based Framework for Multi-Task Cross-Lingual Transfer
[3]: AdaMix: Mixture-of-adaptations for parameter-efficient model tuning
[4]: SparseAdapter: An easy approach for improving the parameter-efficiency of adapters
[5]: Learn-to-Share: A hardware-friendly transfer learning framework exploiting computation and parameter sharing
[6]: Towards a unified view of parameter-efficient transfer learning
[7]: LoRA: Low-rank adaptation of large language models
[8]: DoRA: Weight-decomposed low-rank adaptation
[9]: Prefix-tuning: Optimizing continuous prompts for generation
[10]: Extracting latent steering vectors from pretrained language models
[11]: Activation addition: Steering language models without optimization
[12]: Representation engineering: A top-down approach to AI transparency
[13]: In-context vectors: Making in context learning more effective and controllable through latent space steering
[14]: Inference-time intervention: Eliciting truthful answers from a language model
[15]: Linear adversarial concept erasure
[16]: LEACE: Perfect linear concept erasure in closed form
[17]: What changed? Converting representational interventions to natural language
[18]: MiMiC: Minimally modified counterfactuals in the representation space
[19]: Advancing parameter efficiency in finetuning via representation editing
[20]: Probing for the usage of grammatical number
[21]: Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
[22]: When language models fall in love: Animacy processing in transformer language models
[23]: Identifying and adapting transformer-components responsible for gender bias in an English language model
[24]: Causal abstractions of neural networks